Bloom filter: Application and Implementation
What is a Bloom filter?
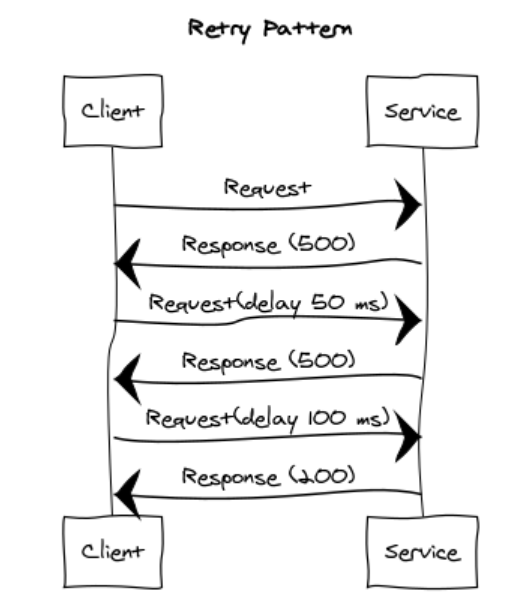
The primary problem that Bloom filters aim to solve is efficient set membership testing while minimizing memory usage. In other words, a Bloom filter is used to quickly determine whether an element is likely a member of a set, without having to store the entire set in memory.
- Bloom filters, use a fixed-size bit array, making them memory-efficient.
- It offers constant-time performance for insertions and queries.
- It can definitely tell you if something is NOT on the list, but if it says something is on the list, it might be wrong.
- Bloom filters can be easily distributed across multiple servers, making them well-suited for large, distributed architectures.
How does Bloom filter works?
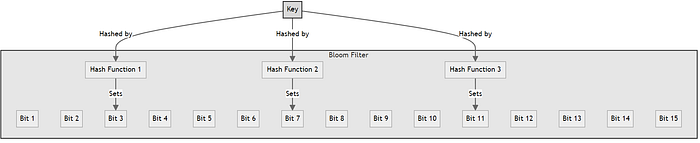
To add an element, it must be hashed using multiple hash functions. Bits are set at the index of the hashes in the bit vector.
For an item whose membership needs to be tested, it is also hashed via the same hash functions. If all the bits are already set for this, the element may exist in the set.
If any bit is not set, the element is definitely not in the set.
Let’s understand it by example
Suppose we need to determine if a specific item exists in a file stored on a computer’s disk. One approach would be to open the file and examine each item it contains. If the item isn’t found, we will close that file and proceed to the next one. This method can be time-consuming, especially when dealing with multiple files or large amounts of data.
However, a more efficient technique involves using a Bloom filter. A Bloom filter is a tool that allows us to quickly check whether the item is likely in the file without having to open and read through the entire file. This process takes a consistent and short amount of time, regardless of the file’s size. While a Bloom filter can confidently indicate that an item is not present, it’s important to note that when it suggests an item is present, there’s a possibility of error. In such cases, we may still need to open the file to verify the item’s presence.
Here’s a breakdown of how a Bloom filter would be used in this context:
Preparation Phase:
- First, create a Bloom filter for each file. While the file is being created or updated, each element (or key) in the file is added to its corresponding Bloom filter.
- Each element is processed through multiple hash functions, and the resulting positions in the bit array of the Bloom filter are set to 1.
Query Phase:
- To check if a specific element is present in a file, you only need to query its corresponding Bloom filter.
- Apply the same hash functions to the element and check the bits at the resulting positions in the Bloom filter.
- If any of these bits is 0, the element is definitely not in the file. If all bits are 1, the element might be in the file.
Why Bloom filters give false positive results
Let’s assume we have added the two keys below to the bloom filter.
- File 1 with Hash Output H(“File1”) = {2,4,5}
- File 2 with Hash Output H(“File2”) = {7,9,3}
Now, if we want to check whether or not File3 exists in the set, we can hash it via the same hash functions.
H(“File3”) = {5,9,3}
We have not added “File3” to the bloom filter, but all the bits at index {5,9,3} have already been set by the previous two elements; thus, Bloom Filter claims that “File3” is present in the set. This is a false positive result.
How to select hash function?
In Bloom filters, hash functions should ideally have two main properties:
- Uniform Distribution: The hash function should distribute the output (hash values) uniformly across the bit array. This ensures that each bit in the array is equally likely to be set, minimizing the chances of collisions and thereby reducing false positives.
- Independence: Multiple hash functions used in a Bloom filter should be independent of each other. This means that the outcome of one hash function should not influence the outcome of another.
What are some of the Hash functions used?
Cryptographic Hash Functions: Functions like SHA-256 or MD5 are sometimes used, especially when uniform distribution is critical. However, cryptographic hashes can be slower, which may be a bottleneck for some applications.
Murmur and City Hash: These are non-cryptographic hash functions designed to be fast and to produce a uniform distribution of hash values.
Bloom filter applications
It has many applications such as:
- Google Chrome uses Bloom filters in its ‘Safe Browsing’ feature. The Bloom filter helps quickly check if a URL is potentially harmful (such as known phishing or malware sites) without sending the actual URL to Google, thus enhancing privacy and speed.
- Medium uses Bloom filters in its Recommendation module to avoid showing those posts that have already been seen by the user.
- Cassandra/HBase uses bloom filters to optimize the search of data in an SSTable on the disk.
- Akamai, a global content delivery network (CDN), uses Bloom filters for its web caching services. They help quickly determine whether a web object is stored in the cache, improving content delivery speed and efficiency.
Drawbacks of Bloom filter
- False Positives: The most significant downside is that while false negatives are impossible (if an element is in the set, the Bloom filter will always confirm it is), false positives are possible.
- Immutable Size: Once created, the size of the Bloom filter cannot be changed without creating a new filter.
- Multiple Hash Functions: The need for multiple, independent, uniformly distributed hash functions can become complex.
Optimal Bloom Filter Parameters: Size and Hash Functions

Guidelines for Calculation:
- Estimate Number of Elements (n): Predict the total elements to be inserted.
- Determine False Positive Rate (P): Choose an acceptable rate; lower rates increase bit array size.
- Calculate Bit Array Size (m): Use the first formula; this impacts memory usage.
- Calculate Hash Functions (k): Use the second formula; this affects time complexity.
Example Calculation:
- For 1,000 elements (n = 1000) and a 1% false positive rate (P = 0.01):
- Bit Array Size (m): ≈9585.77m≈9585.77 bits (round to 9586 bits).
- Number of Hash Functions (k): ≈6.64k≈6.64 (round up to 7 hash functions).
Trade-offs: Balancing false positive rate and memory usage is key. Lower false positive rates require more memory.
Example Usage of Bloom Filter for Cache Penetration
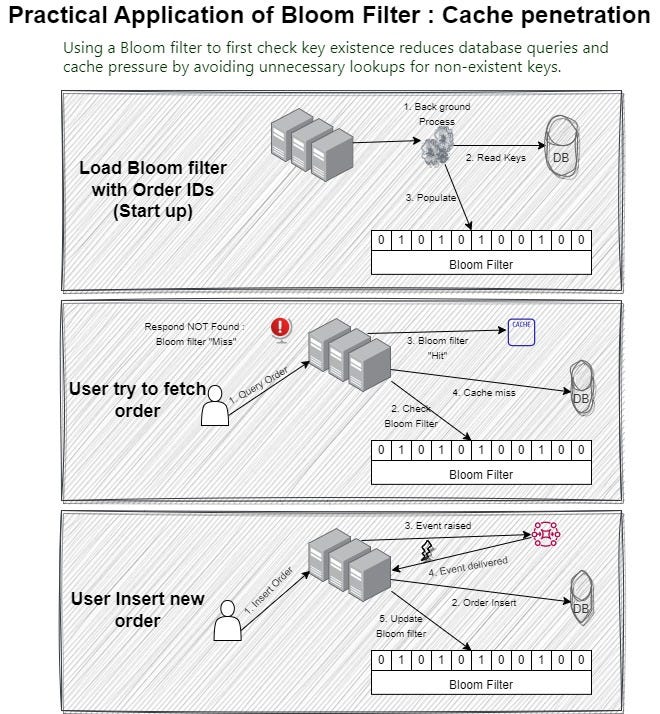
To implement a system using a Bloom filter to reduce database load, especially for non-existent keys, follow these steps:
Initialize the Bloom Filter:
- At startup, initialize a Bloom filter in each service node. Determine the size and number of hash functions based on the expected number of elements and desired false positive rate.
Load Data into the Bloom Filter:
- Load keys from the database to populate the Bloom filter. Set the corresponding bits for each key in the Bloom filter.
- If multiple services or nodes exist, you can copy the populated Bloom filter from one node to others to avoid reloading from the database on each node.
Request Handling:
- For each incoming request, first check the key against the Bloom filter.
- If the Bloom filter indicates the key does not exist (a bit is not set), return a ‘not found’ response immediately, avoiding cache and database lookups.
- If the Bloom filter indicates the key might exist (all bits are set), proceed to check the cache.
Cache Checking:
- If the key exists in the cache (cache hit), return the cached data.
- If the key is not in the cache (cache miss), proceed to query the database.
Database Query:
- Query the database for the key. If found, update the cache with this data and return it.
- If the key is not found in the database, it’s a false positive of the Bloom filter.
Tracking False Positive Rate:
- Monitor the rate of false positives (instances where the Bloom filter indicated a key might exist, but it did not).
- Adjust the Bloom filter parameters (size, number of hash functions) if the false positive rate is higher than acceptable.
Updating Bloom Filter on New Insertions:
- When a new key is inserted into the database, use an event-driven approach to update the Bloom filter on all nodes.
- Publish an event whenever a new key is added to the database. Each service node listens for these events and updates its local Bloom filter accordingly.
Periodic Synchronization (Optional):
- Periodically, or on certain triggers, synchronize the Bloom filter with the database to ensure it reflects the latest data, especially in systems with frequent updates.
Handling Bloom Filter Scalability:
- If the number of elements grows significantly, consider resizing the Bloom filter or using a scalable variant like a Scalable Bloom Filter.
Conclusion
Bloom filters, a memory-efficient data structure used for set membership testing, which offer constant-time performance for insertions and queries but may result in false positives.
Its practical applications in systems like Google Chrome’s Safe Browsing and Medium’s Recommendation module, emphasize its role in improving efficiency and privacy. There are inherent trade-offs involved in Bloom filter design, particularly in balancing false positive rates with memory usage.